2020 was not easy for anyone. And for me personally, I wasn’t able to keep producing content for the community the way that I was used to doing before. Even some of my (usually) crazy IoT experiments that I build, ended up just catching dust on some Github repositories, with no article or more content about them.
Even with 2020 being this crazy year, I ended up having a nice twist by the end of it, when I joined an early-stage IoT startup in San Francisco called golioth.io. The way that the founder and I met each other was due to some of my experiments with IoT, this time one that involved Web Assembly and IoT. You can see the project here and some of the talks here and here.
Enough said, wherever a new year starts, I always try to get back in the game and produce some content to help the dev community. I noticed that has been a while since I wrote an actual article and I was kind of not satisfied with the current state of some of my content being spread between my Github, Medium and YouTube. I was always trying to get my website to be up to date, but the process was too manual. So, I decided to start there and make some changes.
What I want to build
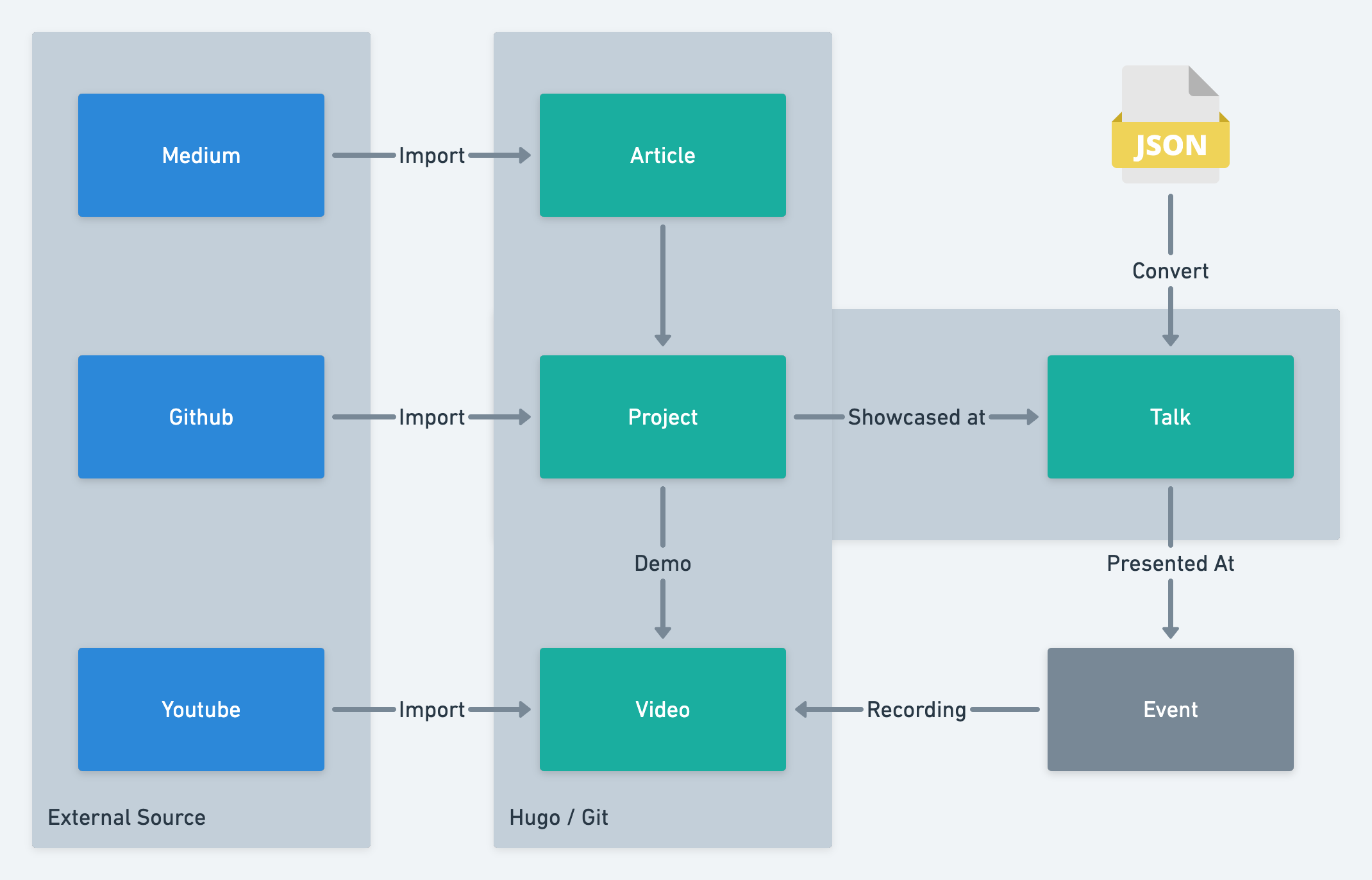
So, as I good engineer, I decided to over-engineer my own personal website and try to put everything into a central place. Here is some of the ideas that I had to build it:
- Show events where I gave a talk and also associate that to a video if it was recorded ( which is kind of the new normal now ). Also show the slides for that talk.
- Show my favorite Github projects and associated them with an article, demo video or talk that I presented that project.
- Export Medium posts to Markdown and maintain on a Git repository so I can really own my articles.
- Use Youtube API to fetch my videos and list on my website.

Relationship between my content and sources
On my (now old) website, I was already maintaining a JSON file with my talks and some projects, so I wanted to reuse that to create the connections that I needed.
Choosing the static website generator tool
My old website was build from scratch using React. But my skills are really low on overall web design and CSS, so it was kind of boring and not that cool. At the same time I wanted something really simple and focused on the content, so one of the big decision factors for me was that the tool that I would select, would have a good set of themes available.
I recently evaluated some tools for a documentation website at work and ended selecting Docusaurus. It’s an awesome tool and I managed to customize it with multiple pages, sidebars and even embedded a SwaggerUI pretty easily, as you can write React in you Markdown files, which by the way, feel like magic. So I was down to use for my personal website too, but I could not find that much themes for it and that was a bummer to me.
So the next tool on my list was Hugo. One cool thing is that Hugo have a lot of themes available and I found this website called Jamstack Themes that has a good selection of themes that I could use.

Hugo Website
Being completely honest, I’m still having a love and hate story with Hugo, because Go/Hugo templates are not as powerful and easy as MDX on Docusaurus, but at the same time, Hugo is blazing fast and have a bigger focus on content. Also Hugo made it relatively easy to separate my content into Talks, Articles, Videos and Projects as I mentioned before, using a feature called archetypes.
I selected this theme called PaperMod, which also had a nice archive view that I ended use using as the default list view for articles, videos and talks. I did that by copying the themes/PaperMod/layouts/_default/archives.html and using as layouts/{articles | videos | talks}/list.html with some changes to match what I wanted.
Now, let’s go through how I migrated my content to Hugo.
Migrating from Medium
I know a lot of people is a bit upset with Medium, as their paywall strategy is at very minimum, weird. My content there is all open and some of reasons why I stayed using Medium for that long is that their editor is really good in my opinion and because of the reach that you can get with their network and publications. For example, I can post on the official Google Cloud publication, which helps me get my content into a lot of people hands.
Quick tip: You can use an Anonymous tab to see any article on Medium without issues. 🏴☠️
But I can keep my articles on my website and cross post to Medium and Dev.to ( or the next big thing that appears ), so sounded like it was a good idea to maintain my articles under my control.
To migrate my Medium articles, I used a tool called mediumtohugo. It basically uses the full data export feature from Medium and convert the exported HTML to Markdown with Frontmatter metadata. So was just a matter of exporting my data and using this command to convert my articles:
./mediumtohugo blog/posts blog/out articles
That gave me all my articles in Markdown format and also downloaded all images, which is pretty cool. Although I have to say that it is not perfect, specially because it failed to import embed content like gists and youtube videos. So what I did was to review all my articles, by adding the embed content missing, formatting images with captions to use Hugo shortcodes and also separating them into folders by year.
Converted this:
![image][./images/1.png]
My Caption
To this:
{{< figure src="./images/1.png" caption="My Caption" >}}
Converting talks to Markdown and import missing data from Slideshare
I was already maintaining a JSON file with all my talks and that was being used by my old website to render them. Here is a sample of a talk registered on it. Basically I can give the same talk on multiple events and also have the link for the slides so people could download it.
{
"title": "Building REST APIs using gRPC and Go",
"slidesUrl": "https://www.slideshare.net/alvarowolfx/building-rest-apis-using-grpc-and-go",
"places": [
{
"name": "Meetup GDG Cloud London",
"date": "11/02/2021",
"local": "Online",
"videoUrl": "https://www.youtube.com/watch?v=yD-DnC5KasI"
}
],
"summary": "Developing APIs over a RESTful interface with JSON..."
}
So I wanted to embed Slideshare on my website, but one problem is that the embed API of Slideshare requires an ID that I didn’t had and it’s not part of the URL. So I wrote a little Web Scrapper in Go that did that work and saved back my JSON file adding a slideID attribute. I used PuerkitoBio/goquery lib to parse HTML and do jQuery like queries on top of it.
That also started a list of scripts that I’m using on my website to generate/sync content.
Also, I needed to convert that JSON to actual Markdown files to show up on the Website. I could have used the Data Templates feature from Hugo ( which I ended up using for Projects - more on that later ), but it is mostly for showing list based on data, I could not figure out a way to access a talk as an single page, so you can see more details like the slides and recording.
So I decided to add another Go script that read all the JSON files and converted each Talk + Event to a Markdown file with the proper Frontmatter metadata. So all markdown files under content/talks are all generated and I’ll keep maintaining my JSON file. I feel that this is more flexible right now, specially because I can give the same talk on another event and still keep the same base data (slides, title, description, etc).
const talkTemplate = `---
title: "[[ .T.Title ]]"
subtitle: "[[ .T.Subtitle ]]"
[[- if gt (len .T.Summary) 2 ]]
summary:
|
[[ .T.Summary ]]
[[- else ]]
summary: " "
[[- end ]]
tags: [[- range .T.Tags ]]
- [[ . ]]
[[- end]]
- talk
cover:
image: "[[ .T.ImageURL ]]"
slidesUrl: "[[ .T.SlidesURL ]]"
slideId: "[[ .T.SlideID ]]"
event: "[[ .P.Name ]]"
audience: "[[ .P.Local ]]"
date: [[ .P.Date ]]
videoUrl: "[[ .P.VideoURL ]]"
video: "[[ .P.VideoID ]]"
---
<!-- truncate -->
{{< param summary >}}
[[- if .P.HaveSlides ]]
### Slides
[[- if ne (len .T.SlideID) 0 ]]
{{< slideshare id=[[ .T.SlideID ]] >}}
[[- end ]]
- [Link to slides]([[ .T.SlidesURL ]])
[[- end]]
[[- if .P.HaveVideo ]]
### Recording
[[- if .P.HaveYoutubeVideo ]]
{{< youtube id=[[ .P.VideoID ]] >}}
[[- end ]]
- [Link to video]([[ .P.VideoURL ]])
[[- end]]
`
)
type TalkPlace struct {
Name string `json:"name"`
Date string `json:"date"`
Local string `json:"local"`
VideoURL string `json:"videoUrl"`
VideoID string `json:"videoId"`
HaveSlides bool
HaveVideo bool
HaveYoutubeVideo bool
}
type Talk struct {
Title string `json:"title"`
ImageURL string `json:"imageUrl"`
SlidesURL string `json:"slidesUrl"`
SlideID string `json:"slideId"`
Places []TalkPlace `json:"places"`
Summary string `json:"summary"`
Subtitle string `json:"subtitle,omitempty"`
Tags []string `json:"tags"`
}
I know, it’s Go text/templates is not pretty, but does the job 🤷♂️.
Show some of my Github Projects
I also maintained another JSON file with the links to my favorite Github projects. Later I’ll probably mark my own Github projects with a special tag and import directly using Github API, but for now the JSON file is fine.
For the projects I used the Data Templates feature from Hugo, because I just wanted to list the project and for now I didn’t have the need to have an actual page for the project, I just wanted to link it to the Github repository and that would force me to maintain a good README file ( by the way, you should always try to write a nice README 😉 ).
But I also wanted to link them to talks and videos that might have showcased those projects, so people can see some demos related to that project. So I added more fields like tags, videos and projects to both talks and videos JSON files to link them together. Bellow you can see an example of “joining” the file with projects and talks. I did a similar thing for other types of content.
// Load JSON files with projects and talks
{{- $pages := $.Site.Data.projects.index }}
{{- $talks := $.Site.Data.talks.index }}
...
// Check which talks match the project repo
{{- $projectTalks := where $talks "projects" "intersect" (slice $repo) }}
See more on this file – Beware, code is not pretty.
Sync YouTube videos
I already built a project using Youtube API in the past, so I thought that it might be a good idea to also sync my videos, by saving them as posts here so I can sync from time to time.

IoT Youtube Display
There are instructions on the Github repo on how to get an API key to access Youtube API, so you check out there. But besides that, the process is close to converting JSON to Markdown + Frontmatter files like I did before. I used Go text/template and the google.golang.org/api/youtube/v3 library to access the API and fetch my uploaded videos. Here is a small subset of the code. I had to do some extra calls to get the tags from the video, so that’s why you can see calls to the PlaylistItems and Videos endpoints. If you don’t need tags, you can just use the PlaylistItems.
import (
"text/template"
youtube "google.golang.org/api/youtube/v3"
)
apiKey := os.Getenv("YOUTUBE_API_KEY")
channelID := os.Getenv("YOUTUBE_CHANNEL_ID")
service, err := youtube.NewService(ctx, option.WithAPIKey(apiKey))
call := service.Channels.List([]string{"contentDetails"}).Id(channelID)
response, err := call.Do()
for _, channel := range response.Items {
playlistId := channel.ContentDetails.RelatedPlaylists.Uploads
nextPageToken := ""
for {
playlistCall := service.PlaylistItems.List([]string{"snippet"}).
PlaylistId(playlistId).
MaxResults(100).
PageToken(nextPageToken)
playlistResponse, _ := playlistCall.Do()
ids := []string{}
for _, playlistItem := range playlistResponse.Items {
videoId := playlistItem.Snippet.ResourceId.VideoId
ids = append(ids, videoId)
}
videoCall := service.Videos.List([]string{"snippet"}).Id(ids...)
videoResponse, err := videoCall.Do()
for _, playlistItem := range videoResponse.Items {
title := playlistItem.Snippet.Title
videoId := playlistItem.Id
videoDate := playlistItem.Snippet.PublishedAt
fmt.Printf("%v, (%v)\r\n", title, videoId)
}
}
nextPageToken = playlistResponse.NextPageToken
if nextPageToken == "" {
break
}
}
Show talks with recording and YouTube videos together
Every person likes to consume content on a given format, it can be either a video, an article or just some code on Github. So for video, I wanted to show all my contents that actually have a video associated to it, not just the videos that I produced directly on Youtube. So a lot of my talks ended being recorded as most of them happened online last year, so I wanted them to show up on the videos page.
To do that with Hugo was really easy. Hugo have a where function that I already showed before that you can filter all pages by a given criteria. In this case I choose the pages that have the archetype talks and videos and later filtered pages that don’t have an videourl attribute, which is an attribute that I maintain on the Frontmatter part of the markdown files.
{{- $tmpPages := where site.RegularPages "Type" "in" (slice "videos" "talks") }}
{{- $pages := where $tmpPages ".Params.videourl" "!=" "" }}
Cross posting to Dev.to
This is something that I’ll experiment with, but I found out that I can sync my articles here to Dev.to by using RSS feeds. I saw this article explaining how to do that, but basically Hugo comes with built-in support for RSS feeds, so I just had to add to Dev.to the link to /article/index.xml and it imported my articles as drafts on Dev.to
Deployment
I was already using Firebase Hosting for deploying the static files, so I just had to change it to work with Hugo. Just running hugo builds the website into the public folder and I can deploy to Firebase as I used to do before.
$ hugo
Start building sites …
| EN
-------------------+------
Pages | 418
Paginator pages | 34
Non-page files | 116
Static files | 2
Processed images | 0
Aliases | 128
Sitemaps | 1
Cleaned | 0
Total in 1180 ms
$ firebase deploy --only hosting
Conclusion
And that’s it, I know that this article ended up being super long, but I just tried to document my over engineering adventure migrating my website and also maintaining all my content in sync. Hope you enjoyed it and maybe that made you want to build you own website and learn some new things in the process.